
Accanto a chi ti siedi in ufficio e perché è importante
Un approccio di network analysis alla vita lavorativa nell’ufficio post-pandemia.
 21 Dicembre 2021
21 Dicembre 2021
 6 min.
6 min.
Introduzione: spazi e dati in un contesto di lavoro ibrido
Con il diffondersi della pandemia, abbiamo tutti imparato a lavorare da remoto; con l’evoluzione dello scenario pandemico, stiamo imparando che possiamo bilanciare il lavoro remoto e quello in presenza in base alle esigenze lavorative. Per questo motivo in tutto il mondo i dipendenti chiedono un maggior grado di libertà nella gestione della propria vita lavorativa. In questa ricerca abbiamo indagato come cambiano le dinamiche di collaborazione, comunicazione e innovazione in un modello operativo di hybrid working.
Infatti, come espresso dal CEO di OpenKnowledge Rosario Sica nell’ultimo allegato di HBR Italia:
Gli spazi di lavoro oggi si trovano in un equilibrio dinamico, in una fase di trasformazione da spaces a places. […]Gli spaces sono i luoghi in cui viviamo e lavoriamo, i places sono i luoghi cui sentiamo di appartenere. Un luogo (place) è fatto di relazioni, è una dimensione sociale in cui il benessere dei dipendenti è realmente messo al centro […]. Le tecnologie e i dati possono aiutare a uscire dalla polverizzazione organizzativa che il remote-working […] ha portato con sè, individuando le community tacite all’interno di un’organizzazione e sostenendo le connessioni libere tra employee. (Sica, 2021)
In questo articolo si indagano le interazioni tra le persone in ufficio utilizzando l’enorme quantità di dati forniti dagli strumenti di hybrid working (in questo caso i dati dello strumento di prenotazione delle scrivanie).
Descrizione dell’esperimento e del modello di dati
Attualmente, nel gruppo BIP, i dipendenti per ogni giorno di frequenza in ufficio sono obbligatoriamente tenuti a prenotare la postazione di lavoro: come detto prima, questa politica ha prodotto un’impressionante quantità grande di dati su dove si siedono i colleghi nella loro quotidianità lavorativa.
Per questa ricerca abbiamo analizzato i dati relativi a OpenKnowledge (circa 100 persone), tra settembre e novembre 2021. L’analisi mira a comprendere la collaborazione e i flussi di conoscenza che avvengono negli spazi condivisi e a misurare la forza delle relazioni osservate utilizzando un approccio di network analysis. Come spesso sottolineato in letteratura (Morten, 1999), i legami deboli (è il caso di colleghi che si incontrano alla macchinetta del caffè, nei corridoi o negli open-space) favoriscono la scoperta e la generazione di nuove idee; al contrario, i legami forti tra persone (come è il caso di colleghi che condividono uno stesso progetto) sono utili quando si tratta di selezionare e rendere operative le nuove idee.
Partendo dall’ipotesi che due persone che condividono gli spazi dello stesso piano dell’edificio nello stesso giorno abbiano una connessione tra loro, abbiamo costruito la corrispondente rete di relazioni tra colleghi. Il modello dei dati assume che la forza dei legami che collegano due persone dipende proporzionalmente dal reciproco della distanza (in metri) tra le loro due postazioni di lavoro.
In particolare, nell’algoritmo utilizzato, legami forti attraggono i nodi alle loro estremità in misura maggiore di quanto lo facciano i legami deboli.
Primo risultato
Utilizzando un classico algoritmo force-directed, Force Atlas 2, abbiamo rappresentato graficamente la mappa delle relazioni fra colleghi: i nodi rappresentano le persone, i legami rappresentano i flussi di collaborazione/conoscenza e i colori dei nodi rappresentano i dipartimenti dell’organizzazione.
Nel grafico sottostante, la dimensione dei nodi è proporzionale al numero di giorni alla settimana in cui ogni persona ha frequentato l’ufficio. Quanto più vicine fra loro si siedono in media le persone, tanto più sono vicine nel grafico.
Come risultato, abbiamo ottenuto una rete complessa e densa (Figura 2), con proprietà che variano al loro interno in diversi ordini di grandezza e una grande quantità di legami deboli, dovute alle assunzioni iniziali del modello di dati. I dati mostrano che esistono alcuni super-nodi (i più grandi) che sono connessi con la maggior parte del grafico. Questo indica che alcune persone venivano spesso in ufficio durante il periodo di analisi e si sedevano in posti considerati “centrali” nella rete. Si consideri che i nodi dello stesso colore spesso non risultano vicini: dunque, un’alta percentuale di relazioni è trasversale ai dipartimenti; l’ufficio quindi si mostra un luogo adatto alla costruzione di relazioni.
Tuttavia, nella rete appena descritta, la capacità di estrarre considerazioni interessanti è limitata dalla grande quantità di legami. Si tratta di una caratteristica ricorrente delle analisi focalizzate sulle digital footprint (le tracce che lasciamo nella nostra vita quotidiana attraverso l’utilizzo di prodotti e servizi digitali): poiché in questi casi i dataset di riferimento sono molto estesi, ne risultano visualizzazioni difficilmente leggibili, ovvero “rumorose”; di conseguenza, è stato necessario un ulteriore passo per rendere il grafico più facile da leggere.
Eliminazione del rumore: network backboning
In un mondo pervaso da informazioni, il rischio di un overload di dati è significativo: in un contesto rumoroso, estrarre intuizioni e prendere decisioni può essere un compito difficile.
Dunque, il problema principale emerso nell’analisi è stato quello di trovare un processo affidabile per selezionare i dati, in modo da evidenziare le informazioni critiche e da eliminare i dati inutili preservando tuttavia le proprietà del grafico (degree, peso dei legami e clustering coefficient). Come menzionato all’inizio di questo articolo, i legami forti e i legami deboli hanno due significati rilevanti (e diversi), e filtrare usando semplicemente il peso dei legami avrebbe portato a una perdita di informazioni. Abbiamo dunque applicato un processo di backboning della rete, sviluppato nel 2008 dagli accademici Serrano, Boguna e Vespignani. Il risultato del processo è “preserving structural properties and hierarchy at all scales” (Serrano et alii, 2009): in breve, il network backboning mira a preservare solo i legami che sono strutturalmente rappresentativi della rete, scartando tutti quei legami che possono essere trovati in una rete casuale ad un determinato livello di probabilità.
Per inizializzare l’algoritmo di filtering, abbiamo impostato un parametro α di probabilità (che va da 0 a 1), che serve a determinare se il peso di un collegamento è compatibile o meno con uno scenario random: in caso positivo (compatibilità è maggiore di α) il collegamento viene scartato, altrimenti mantenuto. I grafici riportati di seguito mostrano come variano le distribuzioni di degree, peso dei collegamenti e clustering coefficient al variare di α in scenari generati in Python [1].
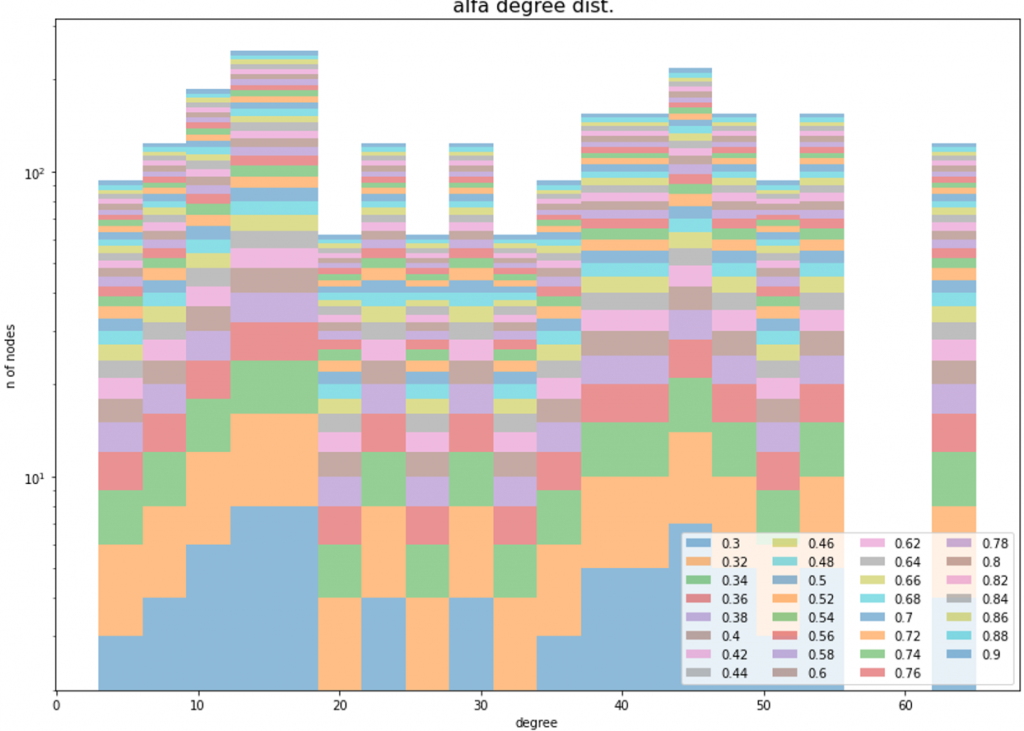
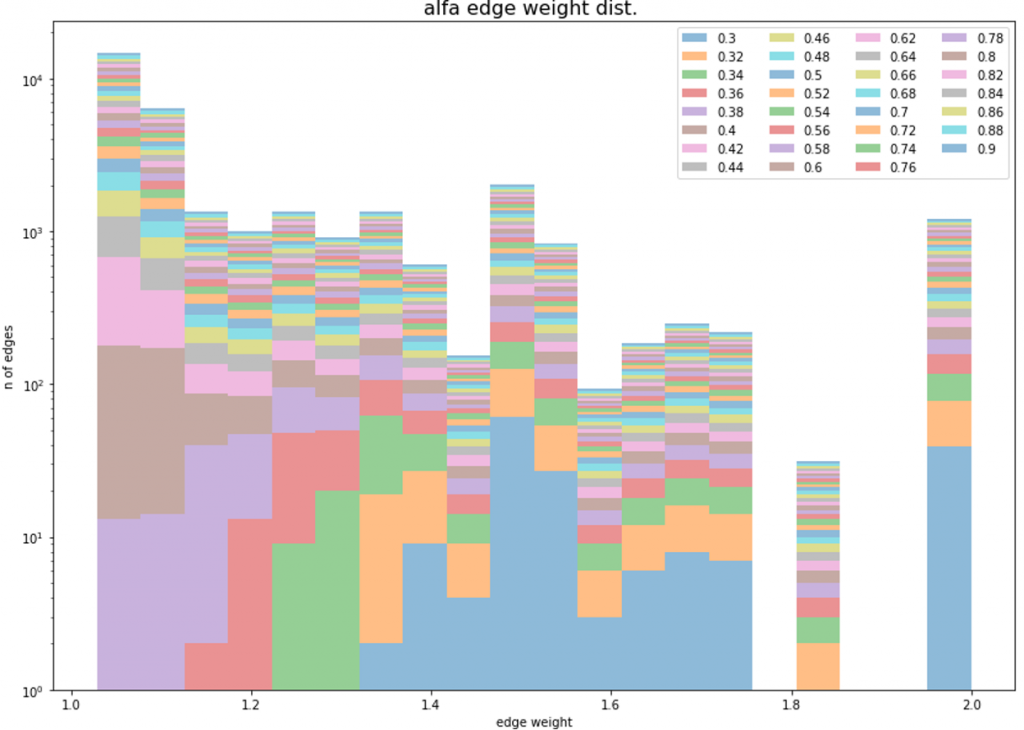
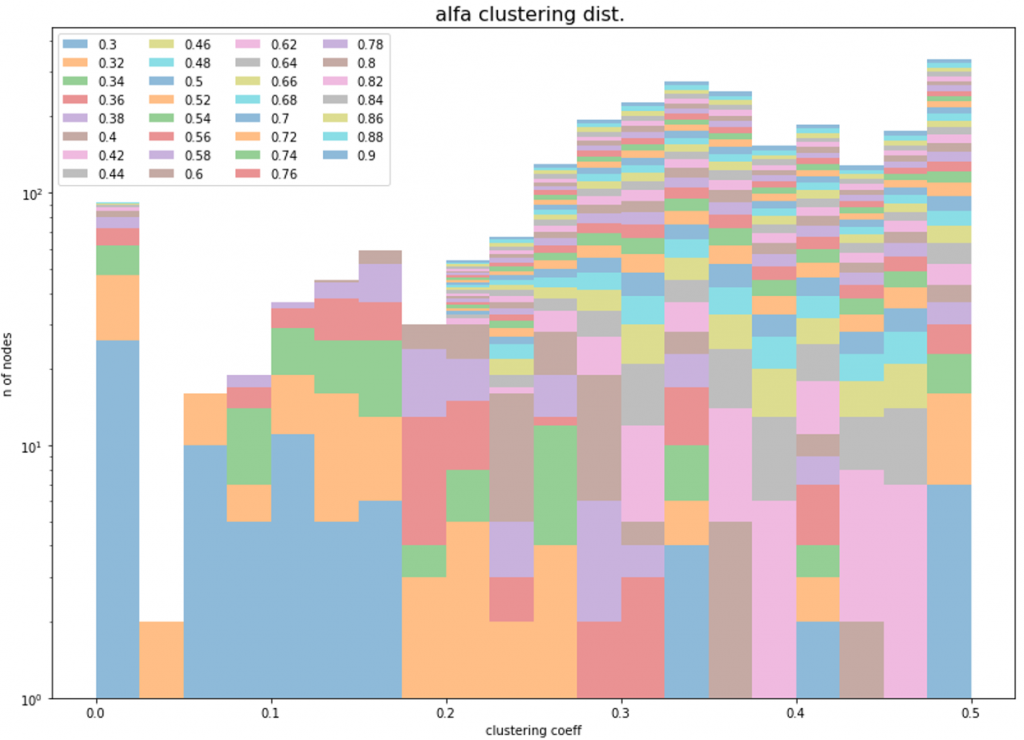
Figura 2: Distribuzioni di degree, edge weight, clustering coefficient al variare di α
Sulla base dei risultati ottenuti, abbiamo scelto un α pari a 0,38. Questo valore consente di:
· eliminare una parte considerevole dei legami;
· mantenere inalterata la distribuzione dei degree, la distribuzione dei pesi dei collegamenti e la distribuzione dei clustering coefficient;
· rendere la rete più leggibile.
[1] Per gli scenari con α, abbiamo utilizzato il pacchetto Phyton che si può trovare qui su Github https://github.com/aekpalakorn/python-backbone-network/blob/master/backbone.py
Risultato finale
L’immagine seguente costituisce il risultato del processo di filtering applicato alla rete iniziale con una soglia di α pari a 0.38.

Nel grafico finale, 53 nodi su 86 (61%) sono ancora connessi: questo rappresenta la “spina dorsale” della rete originale, o network backbone. Qui di seguito riportiamo i principali risultati:
- Due grandi nodi risultano essere piuttosto isolati: il nodo verde sul lato sinistro del grafico e quello grigio sul lato destro; questi nodi sono visitatori regolari dell’ufficio, ma abituati a sedersi da soli in scrivanie lontane dalla maggioranza dei colleghi.
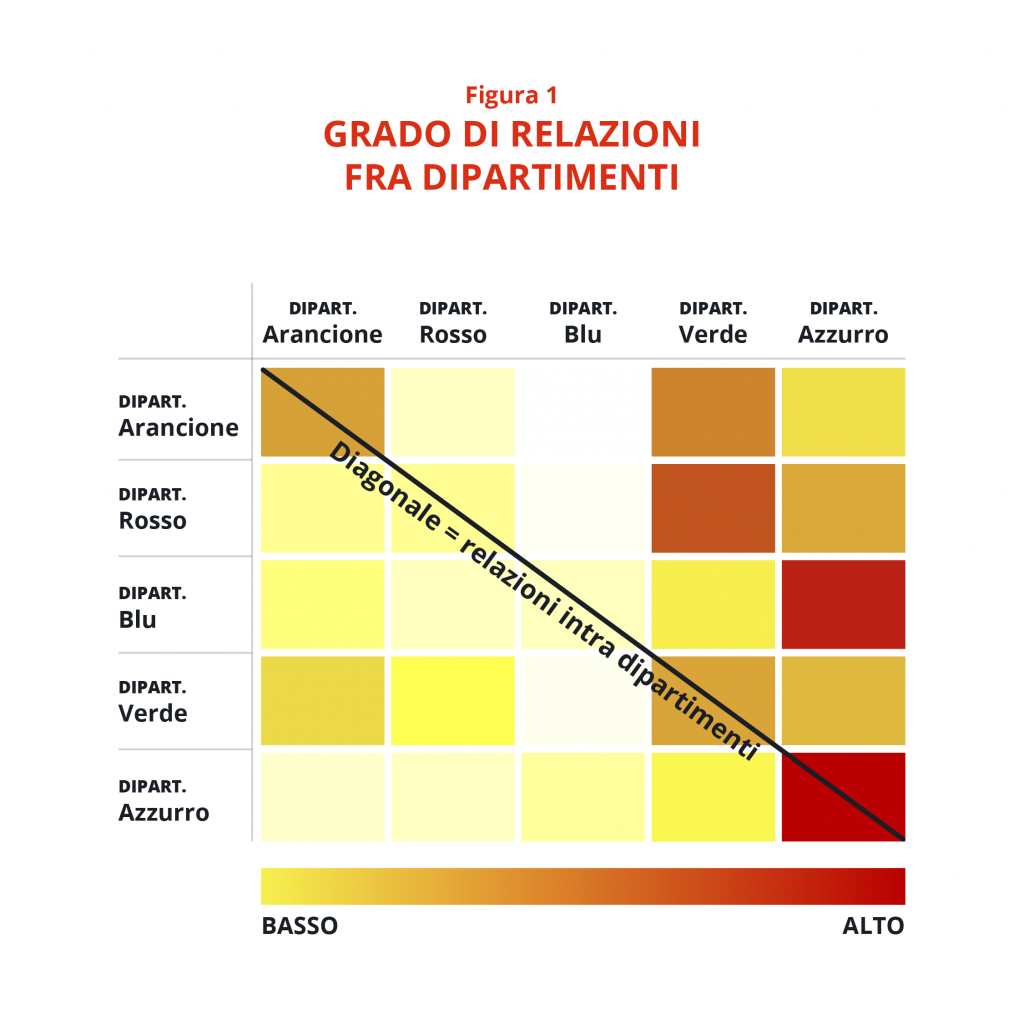
- Due dipartimenti emergono come cluster significativi (quello azzurro e quello verde); da un’ulteriore indagine, è risultato che i colleghi di questi dipartimenti tendono a concordare la presenza in ufficio. A seguito di un’ulteriore analisi sui legami intra e interdipartimentali (Tabella 1), è risultato che la maggior parte delle relazioni di ogni dipartimento (vedi celle più scure nella heatmap) sono condivise con altri dipartimenti, ad eccezione del dipartimento di colore azzurro.
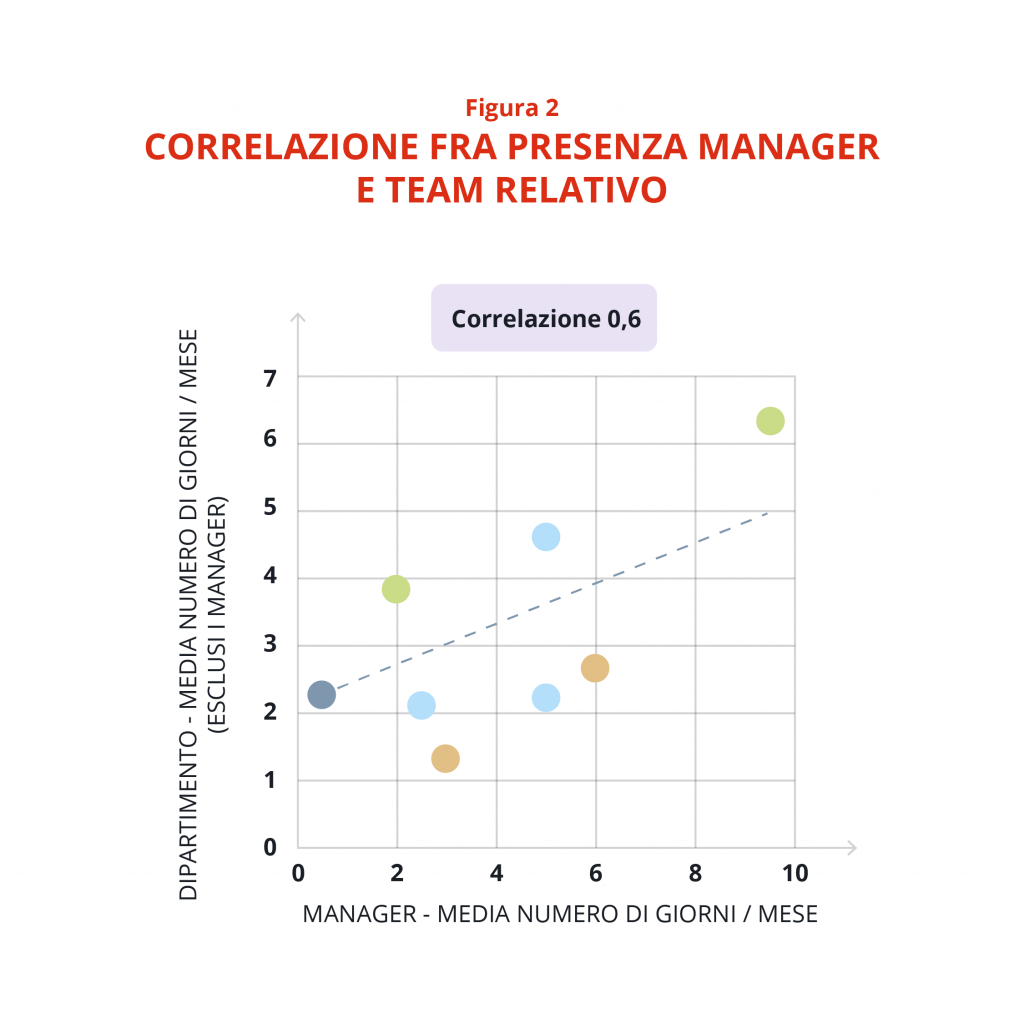
- I manager con un’alta seniority e i partner che frequentano l’ufficio tendono ad avere molti legami forti. Inoltre, una correlazione positiva tra la presenza dei manager in ufficio e la presenza dei loro collaboratori suggerisce che le persone tendono ad andare in ufficio quando il loro diretto responsabile è presente (Tabella 2).
Conclusioni
Un modello in cui si può scegliere liberamente se frequentare o meno il posto di lavoro non porta ad avere uffici vuoti: offre maggiori opportunità di migliorare l’equilibrio fra vita e lavoro e favorisce la creazione di legami deboli aumentando le occasioni di incontro casuale. Questa componente di casualità contribuisce ad abbattere i silos; altrimenti, in uno scenario di lavoro completamente da remoto le persone tendono a parlare ogni giorno con gli stessi colleghi a cui sono legati da rapporti di amicizia o di collaborazione negli stessi progetti. Dunque, la casualità favorisce la creazione di legami deboli e lo scambio di conoscenze ed idee, al contrario di quanto facciano routine regolari, l’assegnazione fissa delle postazioni di lavoro e rigide regole di presenza.
In conclusione, l’hybrid working e delle policy di frequenza libera in ufficio risultano essere una buona strategia per consentire sia un ritrovato equilibrio tra vita personale e professionale, sia la creazione di valore aggiunto tramite lo scambio di idee in occasioni di incontro non programmate. Questa soluzione, facendo collimare così gli interessi dei lavoratori con quelli delle aziende, può riavviare il motore dell’innovazione dopo due anni di incertezza e distacco.
Bibliografia
Sica R. (2021), Introduzione, in Il tempo ritrovato, inserto redazionale di HBR Italia, December 2021, p. 7, our translation.
Morten T. H. (1999), The Search-Transfer Problem: The Role of Weak Ties in Sharing Knowledge across Organization Subunit, in Administrative Science Quarterly, 44, 1999, pp. 82-111.
Serrano M. A., Boguñáb M, Vespignani A. (2009), Extracting the multiscale backbone of complex weighted networks, in PNAS, April 2009, vol. 106, no. 16, p. 6483
Autori: Francesca Guzzetti, Adriano Cecconi, Federico Dottori